Spock Proxy supports range-based horizontal paritioning of a large MySQL database. The proxy intercepts SQL queries from the client, sends queries to the correct databases based on how the database is partitioned, then aggregates the results from each database and returns them to the client as a regular MySQL result set.
Spock Proxy's original mandate was to horizontally partition Spock's existing monolithic databases into multiple shards to improve performance and scalability.
Whereas many web sites build sharding logic into the application, Spock is built on Rails and ActiveRecord. We love Rails, but it doesn't make partitioning easy. So, we preferred to partition at the MySQL level. The application sends a SQL statement to the proxy. The proxy then sends the statement to one or more databases based the value of a column in a predefined column. Finally the proxy returns a merged result.
We target applications that are interested in partitioning but want to avoid large changes to their existing application code.
Grab a tarball release from our SourceForge site. Or grab the latest code from trunk.
./autogen.sh
./configure && make
To see Spock Proxy in action, take a look at sample/README in the distribution. It lets you quickly create some sample tables, populates them with data, and you can immediately start issuing queries.
Now that you've played with the sample, let's set this up for real.
Supporting a dynamic connection pool requires connection information for each database. Rather than add a gazillion command-line parameters, we opted for reading the configuration directly out of a MySQL database.
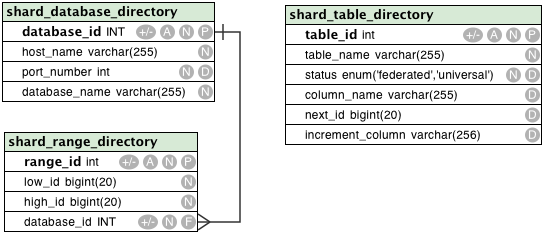
Contains the list of hostnames, database names, ports, that define the database servers that Spock Proxy will connect to. These are where the shards live (note: if you're just testing they do not have to be on seporate machines just give them different DB names). This schema is subject to change while Spock Proxy is in alpha.
Defines which tables and column names are partitioned and should be redirected to a specific database connection (status = 'federated') and which are not (status = 'universal'). This schema is subject to change while Spock Proxy is in alpha.
A lookup table used to define ranges in a column's ID (defined in shard_table_directory) and which database (defined in the shard_database_directory) to send that command to. Note that ranges are the same across all tables so that you can JOIN between tables on the same partition. This schema is subject to change while Spock Proxy is in alpha.
This is a stored function that will increment the shard_table_directory.increment_column. It is used by the proxy for insert statements as a replacement for auto_increment. But you can also call it yourself to get one or many id's for your table. You might want to call this yourself it you wanted to bulk load data and needed some number of id's. To call it:
SELECT get_next_id('person', 10);
The above would have returned the next id available in the person table and incremented it by 10. It will always return a single integer, if you asked for 10 start at the one given and use the next 9.
Running Spock Proxy itself requires passing a few options:
./spockproxy --proxy-address=127.0.0.1:3325 --admin-address=127.0.0.1:3324 --partition-info-host=database_name --partition-info-database=database_universal_production --db-user=database_user --db-user-password=abcdefg > ./spockproxy.log 2> ./spockproxy.err
Spock Proxy is a fork of MySQL Proxy. Large portions of the code are unchanged, but the architecture is fundamentally different.
MySQL Proxy supports using the Lua scripting language for customization, but Spock Proxy does not. Although Lua is considered a good scripting language, we were concerned about performance, especially in consolidating result sets. The time required to copy N database results sets into Lua structures, merge within Lua, and then copy them back out into 'C' space required too much overhead. Lua was entirely abandoned and we hard-coded a C/C++ implementation. The design however is to support the MySQL Proxy callback idea, but by passing mutable C structures to a shared library. This shared library can then be implemented in C and of course if so desired in Lua again.
MySQL Proxy allows each client to directly authenticate with each database. This is problematic because the client has to establish the minimum connections up-front before the proxy will work. During normal operation, if any of those 'cached' connections is lost or disconnected, the client may not gain access to that database if a connection is not reestablished. Spock Proxy is designed to separate server connections from the client. Spock Proxy automatically authenticates clients using the username/password you specify at startup.
Spock Proxy separates the client from the server connections, allowing a minimum and maximum connection size to be managed. Upon startup the proxy establishes a connection pool with the minimum number of connections. After that, each time a client uses a connection, it is his for the life of the connection. A new connection will be established to maintain that minimum connection pool on a per hostname/database/username basis. In the event all connections are dropped a maximum is defined and connections above that count will be dropped if not used after a minimum time period. If you expect a large number of random connections, you can change the minimum connection count to prevent waiting for the server to connect.
We based Spock Proxy on MySQL Proxy because it sounded from the web site that it would meet our sharding requirements with some Lua coding. We first started by trying to use the Read-Write Splitter Lua script; however, the code didn�t appear to work correctly. After some struggles we realized that although MySQL Proxy managed existing connections it did not create them. This would require a client to establish a bunch of connections before any web server could send a request. Further analysis indicated only one database could be sent a request at a time. This implementation would not work for Spock which required consolidation of data across multiple partitions.
Sending multiple server requests and consolidating those results was part of our original design. To ensure maximum speed, all of the sends are broadcasted at once and the reads performed asynchronously. Upon read completion of all of the result sets from each database, if the count is greater then one (1), the merge code is called. If there is only one (1) result set, the data is automatically forwarded to the client. If any error is returned from any database, an error will be sent back to the client.
MySQL Cluster was designed for high availability and performance, not for sharding. All indices and the main data are stored in main memory, which causes problems if your combined dataset is larger than memory. It also requires changing storage engines.
HiveDB has similar goals as Spock Proxy but requires running a JVM in production and most of its functionality is behind a Java-based API, with multi-language support in its infancy. Not ideal for Rails or PHP sites.
Not all queries supported by MySQL are fully supported by Spock Proxy. When the proxy fails in parsing the query, the caller will get an error or get relayed to the partition info database.
Here are the known issues:
Since the data is spread across several shards it is not possible for a shard to know what the last id that was assigned in a certain table. If the record to be inserted is for the table who is federated on its primary key then we don't even know the value so we can't direct it to the correct shard.
Even tables where the key might seem less important shards could generate duplicate values. You could set auto_increment_increment and auto_increment_offset to avoid conflicts but rearranging the shards requires rearranging these values and it could be quite cumbersome.
Our solution is for the proxy to intercept INSERT statements and to handle the increment values for you. We store the values and the increment column in the shard_table_directory table. You will need to set them up with the correct values for this to work. You can also access these values and get one id or as many as you want through the function get_next_id.
SELECT get_next_id(< table_name >, < number of id's you want >);
This can be very handy for bulk loading or other external processing, it might be necessary if you need the insert_id since that call doesn't work either.
As you organize your tables to implement federation your tables will fall into one of four categories (below). For example, if you had a dating web site and many many millions of users. You decide to fererate the database on user_id. Your user table has a user_id as primary key which you can use to divide this table. The other table will be one of these:
The last case is the most difficult. In the example here I choose to use from_user_id to federate because it is more likely that users will open their in box and want to see the messages joined to users on from_user_id. The query:
SELECT * FROM users, messages WHERE from_user_id = user_id AND to_user_id = 12345;
will be sent to all shards and the results will be combined. This is what we want. If you want to show the sent mail for a particular user you will have to do the join in your application using multile queries:
SELECT * FROM messages WHERE from_user_id = 12345;
SELECT * FROM users WHERE user_id = 234;
SELECT * FROM users WHERE user_id = 5678;
SELECT * FROM users WHERE user_id = 9753;
SELECT * FROM users WHERE user_id = 23435;
SELECT * FROM users WHERE user_id = 5654;
That list of user_id's came from the first query. You might consider de-normalizing so you never have to do this.
Unlike a single insert which the proxy can pass to the appropriate shard a bulk load contains multiple rows and it is possible that these rows will belong in different shards. The proxy does not support bulk loading either INSERT statements with multiple rows or LOAD DATA INFILE.
The two ways to work around this are to either break the INSERT statements into single statements or to insert directly into the shards. Splitting the inserts into separate statements is very straight forward but it can be slow as you loose all of the speed advantages of bulk loading.
Inserting directly into the shards is currently the most practical option for large amounts of data. We have found this method can be faster than bulk load into a single database as the writes are distributed over all of the shards. One way to accomplish this is to use a perl script to divide the load

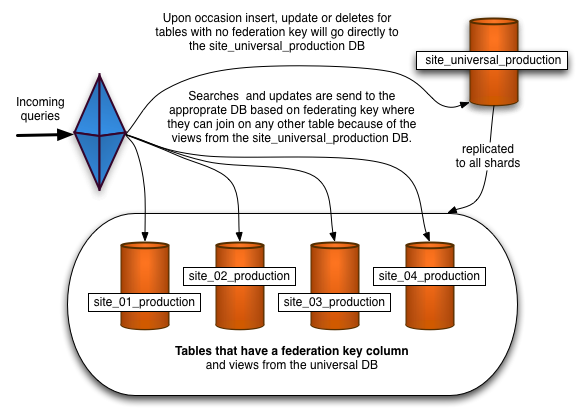
As mentioned above some tables will need to be in each shard so joins will work. In the example above we federated the database on the user_id so that all of the records related to a particular user_id would reside in the same shard. Now imagine a table 'cities'; any user can live in any city so city_id does not imply a user_id and it is likely that a particular city_id is referenced from each shard. The entire cities table must be included in each shard.
There are several ways to accomplish this. We have solved it by having a 'universal' database which contains all of these tables as well as some directory tables. Each shard database is a slave of this universal database server and the universal database is replicated to each shard. There are two databases on each shard, the shard itself which is unique to that shard (and perhaps it's slaves) and the universal database which is identical to all other universal databases. Finally for compatibility there is a view for every table in the local universal database in the shard. This allows the queries to work that join federated and universal tables. This solution works well but there can be a slight lag in records showing up in the shard from when it's inserted into a universal table.
Normally tables are partitioned on different columns, so they can be stored on different machines. Some tables are not partitioned, either because they are too small or otherwise will cause table join to not work properly. Partitioned tables usually are stored across all the machines in the partition cluster. Non-partition tables stay in one master node, but a read-only view for each non-partitioned table is available on each machine in the partition cluster. Partitioned tables can be partitioned on different columns, but in order for join to work properly, they all share the same partition table in which you can specify which part of the tables to be stored on which hosts. In our example, table database_list has the list of all the databases in the partition cluster, table directory_table has the information about whether a table is partitioned or not, if so, what column it is based on, table directory has list of id ranges telling which part of the partitioned tables should be stored on which database.
Given an id, in order to find quickly which partition the query goes to, two levels of data structures is used. The underline level is a dynamic array sorted on the ranges, so we can do a binary search. In order to avoid doing a binary search on the whole list, we build another dynamic array in which for every M ids we build their start offset and end offset in the first array, search time in this array is O(1).
When an insertion contains an id, and this id happens to be the partitioned column and its type is auto increment, we need to assign the id first, otherwise we do not know which partition this query should go to. In our implementation, we have a separate thread to prefetch a number of such IDs regularly so we can assign them later when needed.
resultset_merge() merges multiple replies from servers into one reply.
On queries sending to multiple servers, Spock Proxy expects multiple replies from servers which could be OK packets, Error packets or resultset packets. However, the client wants a single reply. resultset_merge merges results to give one valid result back to the client.
The current interface between main body of proxy and resultset_merge is :
Input:
Output:
And when there is only one server responding, the proxy handle it by itself instead of calling resultset_merge(). Only under following circumstances, resultset_merge() will be called:
After calling resultset_merge(), the proxy does nothing but sending all packets in send_queue.
On resultset packets, resultset_merge() is doing merge-sort in effect:
On OK packets, resultset_merge() counts rows affected by scanning all OK packets and appends a new OK packet with total rows affected into send_queue.
On Error packets, the very first incoming Error packet is appended into send_queue.
Space complexity: O(1)
Time complexity: O( min(Limit in Query, Total number of results * Number of recv_queues) )
Policies:
In this way, the client will always expect a single valid result as if it is always talking to a single server.
Join the spockproxy-devel mailing list if you have questions or to submit a patch.
Spock Proxy was created by engineers at Spock, the leading people search engine that helps you find friends and colleagues on the Web.
Coded by:
Testing help from Frank Flynn and Oleg Polyakov. Moral support from Ravi Someshwar, Jeff Winner, and Wayne Kao.